
Randomised Controlled Trials (RCTs) have become very popular in the education sector. Hugues Lortie-Forgues and Matthew Inglis recently re-analysed trials conducted by the Education Endowment Foundation (EEF) in the UK and the National Center on Education and the Economy in the United States – two of the largest funders of education RCTs in the world. They wanted to get a sense of how informative this approach has actually been.
What did they find? That many of the trials to date have produced small effects, and many have had wide confidence intervals - the combination of the two limiting what we can learn from the trials.
But as Carrie Bradshaw might say, it got me wondering: if some of these trials weren’t telling us a lot, were we learning from them anyway?
The whole premise of the ‘What Works’ movement is that we keep learning not just about what works, but about the best ways to find those answers. By taking a close look at how the EEF’s approach has changed over time, I think we see a powerful example of an organisation that’s doing just that.
The challenges of being a trailblazer
For the EEF, one of the disadvantages of being the largest producer of education RCTs, and trailblazing their use at a large scale, is that there wasn’t a lot of evidence to go on at the start (in 2011).
I began running trials in public policy about a year after the EEF and I remember the finger-in-the-air nature of our sample size calculations at the time. We were in a world of figures like John Hattie, whose meta analysis of effect sizes in education calculated the average effect size as 1 standard deviation. The early EEF trials were powered to detect effects like this.
Early results fairly quickly discredited this accepted wisdom. The trials were underpowered, with too few participants. A lot of this is to the great credit of the EEF. By holding the line on quality (their trials are independently evaluated and rigorously protocolised) and being transparent in reporting results, they have overcome many of the factors - like publication bias - which inflate effect sizes in a lot of existing academic research.
Without question, calibrating the “right” size and number of trials to run in the absence of reliable evidence on effect sizes is tricky. There are ethical issues around running “overpowered” studies as well. Each RCT requires spending scarce resources, both in terms of money and teachers’ time and effort, and means withholding a potentially useful treatment from some people, at random. Crudely, if there were 100 schools in Britain who wanted to run trials, you can choose to run one large trial, two medium-sized ones, or 10 small ones. Your 100-school trial would definitely give you a clearer answer to one question than your ten small ones, but only to one question (and we have no shortage of questions to answer).
The What Works ethos
So what you should do, if you realise that your initial assumptions about likely effect sizes were wrong? You should update those assumptions and do things differently. Reviewing the back catalogue of EEF trials, it’s clear that’s exactly what they did.
If you take a look at the effective sample size of EEF trials over time, you see a significant rise in effect sample, with a particularly prominent increase (almost doubling) in 2014 – around the time that the first trials started producing results (see the figure below). So EEF trials have got larger, and hence more informative, over time.
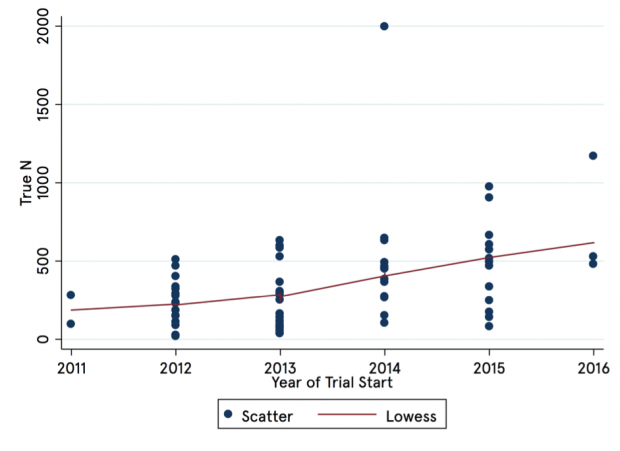
Graph illustrating the size of EEF trials between 2011 and 2016
It’s easy for us to think about “What Works” as a static process, and an RCT as a tool to be used, almost mechanically, for us to uncover the truth. Neither of these is true. Instead, the What Works movement is, well, always moving. We need to keep learning not just about what works, but about the best ways to unearth those answers. We should be sensible enough to make changes to our approach when things don’t go to plan, or when our initial assumptions turn out to be wrong. That means being as rigorous in our assessment of our own work as we are in our attempts to evaluate others. I’m very glad to see the EEF doing that.
Methodological Note:
There are multiple ways to assess how well powered a study is, some of them more complicated than others. I have taken here as a guide ‘true’ sample size. True sample size is calculated based on the amount of independent observations’ worth of data there are in each arm of a randomised trial. To do this, I took per-arm sample size from all published EEF trials (77 trials), and adjusted for the randomisation strategy. In particular, if a trial was cluster randomised at either the level of the class or the school, I calculated a design effect assuming an intra-cluster correlation rate of 0.15 (that which is usually used in ex ante power calculations for EEF trials), and homogeneous cluster sizes. This approach is imperfect, as it does not account for, for example, controlling for prior attainment, which is often and increasingly done in EEF trials, or for heterogeneity in cluster sizes. To the extent that these factors bias my estimates of effect sizes, they are in general either constant over time (as with cluster sizes), or bias the ‘true’ sample size figures downwards, and particularly for those trials which began later, meaning that my estimates of increasing sample size are, if incorrect, understating the case. Trial year is determined here as the calendar year in which the intervention began according to the EEF’s trial protocol.
Leave a comment